We make hundreds of micro-decisions every day. Some are trivial—like choosing which coffee to order. But others? They can change everything.
Let's talk about one of those big decisions: buying a used car.
I've seen this scenario play out dozens of times with students and friends. You're standing in a car lot on a Saturday afternoon, staring at a Honda Civic with 85,000 miles on it. The salesperson is hovering nearby, waiting for you to make a move. Your brain is racing: "Is this car a gem that'll run for another 100,000 miles? Or is it a lemon that'll break down next month?"
You can't just flip a coin. You need a systematic way to filter through the noise. And that's exactly what decision tree algorithms do—they model how we actually think when making these complex choices.
The Data You're Already Collecting (Even If You Don't Realize It)
Here's what's happening in your head, whether you're aware of it or not. You have a mental checklist of features (we call these dimensions in data science):
- Mileage — How much has it been driven?
- Accident History — Has it been wrecked?
- Age — Is this thing ancient or relatively new?
Let's say you have data from five similar cars you've researched:
| Car ID | Mileage | Accident History | Age | Decision |
|---|---|---|---|---|
| #1 | Low | None | New | BUY |
| #2 | High | Crash | Old | DON'T BUY |
| #3 | Low | Crash | New | DON'T BUY |
| #4 | High | None | Old | DON'T BUY |
| #5 | Low | None | Old | BUY |
The problem? Real life is messy. You can't just say "Buy all cars with Low Mileage," because look at Car #3—low mileage, but it was in a crash. That's a deal-breaker for most people. You need a model that captures these nuances.
What "Success" Looks Like: The Perfect Split
Before we build the model, let's define what we're aiming for. Imagine you could ask one single question that would magically separate the cars into two perfectly clean piles:
- Pile A: 100% Good Cars
- Pile B: 100% Lemons
This is the Holy Grail of classification—what we call High Purity. If you ask a useless question like "Is the car red?", your piles will still be a jumbled mess of good and bad cars. That's a terrible question.
But if you ask "Has it been in a crash?", suddenly Pile B (the "Yes" pile) might be entirely filled with cars you shouldn't buy. That's a powerful question. The goal of our algorithm is to find the questions that maximize this separation.
Enter the Decision Tree: A Systematic Approach
This is where the decision tree algorithm comes in. It doesn't guess randomly—it follows a rigorous, step-by-step logic to find the best questions to ask at each stage.
Step 1: The Root Node (The First Question)
The algorithm scans through all the features in your dataset and calculates which one creates the cleanest split. In our case, it determines that Accident History is the biggest deal-breaker.
Question: Had a crash?
- YES: DON'T BUY. (This group is pure. We stop here.)
- NO: We still have a mix of cars—some worth buying, some not. We need to dig deeper.
Step 2: The Branching (Refining the Decision)
For the cars that have never crashed, we need another filter. The algorithm looks at the remaining data and picks the next best feature: Mileage.
Question: Is Mileage High?
- YES: DON'T BUY.
- NO: BUY.
The Final Structure: A Simple Flowchart
In the end, you get a clean flowchart that looks like this:
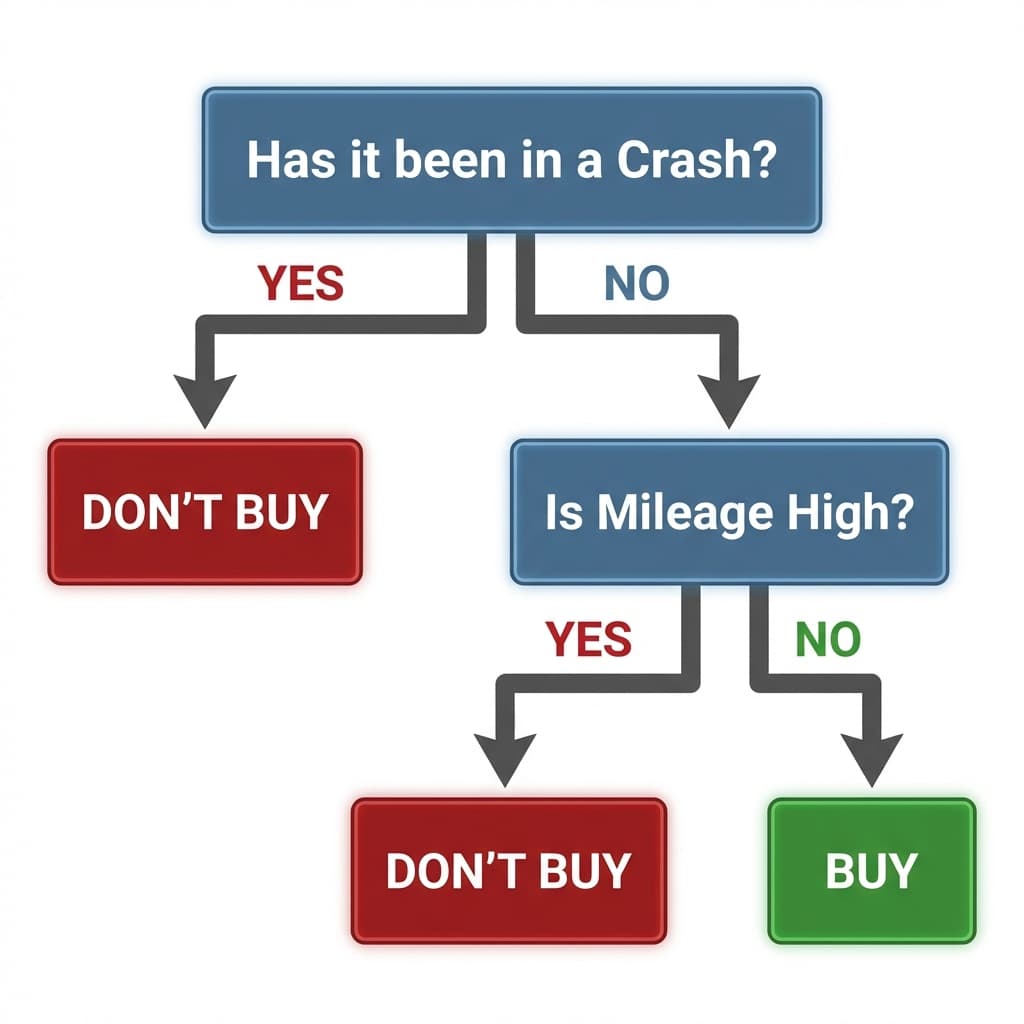
A visual representation of the decision tree logic: crash history first, then mileage
- Nodes: The specific features we're checking (Accident History, Mileage)
- Branches: The possible answers (Yes/No)
- Leaves: The final verdict (Buy/Don't Buy)
This structure turns a messy spreadsheet into a simple, step-by-step rulebook that anyone can follow.
The Real Question: How Did the Machine Know?
Now, here's where it gets interesting. You might be wondering:
💭"Wait, how did the machine know that 'Accident History' was better than 'Mileage' to start with?"
Why didn't we put Mileage at the root instead? How do we mathematically prove which feature creates the cleanest split?
We can't just rely on gut feeling or intuition here. We need a mathematical way to calculate exactly which feature creates the cleanest split. We need to put a precise number on "Purity."
In data science, we use two famous metrics for this:
- Information Gain (based on Entropy)
- Gini Coefficient
These formulas might sound intimidating, but they're actually elegant solutions to a simple problem: How do I measure disorder in my data?
But that involves a bit of math, so we'll save that deep dive for the next article. If you want to truly understand decision trees at a granular level, you'll need to grasp these concepts—and I promise to make them just as intuitive as this car-buying example.
What I Learned from Teaching This
Over the years, I've noticed that students who understand decision trees through real-world analogies (like this used car example) tend to grasp the mathematical formulas much faster than those who jump straight into entropy calculations.
Why? Because they've already built the mental model. They understand why we need to measure purity, why we split on certain features, and why the algorithm stops when it reaches a "pure" leaf node.
Try It Yourself
Want to see decision trees in action? Check out our comprehensive Decision Trees Course, where we cover:
- ✓ Information Gain and Entropy calculations
- ✓ ID3, C4.5, and CART algorithms
- ✓ Overfitting and pruning techniques
- ✓ Real-world implementation examples
Next Steps
In the next article, we'll tackle the math behind Information Gain and show you exactly how the algorithm calculates which question to ask first. I'll use the same intuitive, step-by-step approach—no heavy jargon, just clear explanations.
Until then, try thinking about other decisions you make daily. Can you spot the "decision tree" logic hiding in your thought process? That's the first step to truly understanding machine learning—recognizing that these algorithms mirror how we already think.